Kylin 和 Doris:新时代已经到来
前情提要
恕本人短见,在做这份工作前,我从来没有听说过 kylin,这一位完全由中国程序员开发开源的分布式 OLAP 计算引擎,在这之前,你和我说 kylin,我以为是哪个 linux 操作系统版本。得益于一个新项目,用户指定要安装 kylin,然后主管把任务分到我头上,把 kylin 集合到系统里,我才了解到 kylin 这个组件。
然后因为本人的“猖狂”,在转正答辩上,我侃侃而谈,提了嘴自己认为doris 其实是完全比kylin 好的。然后一位领导在我答完后像我提问:
Doris 和 Kylin 的差异?为什么 doris 更好,为什么不用 kylin?
当时我只是整合 kylin 到系统里,说真的就是只是做了做安装和部署,我只是大约了解了 cube,kylin 是维度聚合什么的,只能扯东扯西,最后说到 doris 社区很火热,kylin 社区比较“冷”,截止今日,我去 github 看了看,(吔,竟然在 25.12.2 号竟然有新的提交,打脸了),不过活动的确是比较少了,更多是维护。我说到这生硬结尾了。
领导没说什么,答辩后第二天私发了条信息给我

好吧,本人脸红了,的确不懂的情况下就大肆评价,的确颇有失偏颇。主要是受 AI 热潮影响,认为新就是好,热就是好,所以以此为题,讲讲我眼里的“老东西” Kylin ,和我认为的“新东西”:Doris。
1.Kylin:麒麟,来自中国
既然讲到社区,那就先不一上来就扯架构,扯作用,先叙说一下 kylin 的历史。 说到社区比较冷,根据时效性来说是目前比较冷,不能代表他之前冷,看一个项目,不能光顾看他的代码,也要看看他的历史,不查不知道,一查吓一跳——
在 2015 年之前,apache孵化支持的项目多达300 个,然后有 162 顶级项目,但是这个 162 个里,没有一个来自中国。 但是十年前这个尴尬场面,不久后就由一个”中国瑞兽“打破了,
”第一个由中国团队完整贡献到 Apache 的顶级项目诞生了,它就是 Apache Kylin(麒麟)。而从最初开源到成为 Apache 顶级项目,Apache Kylin 只花了 13 个月。“^1
kylin 最初孵化于 eBay(跨境老资历),当初难点就是交易数据非常大,hive+hadoop 查询太慢了,领导要个数据,你只能尴尬的说在跑。。。查询比较慢,所以就有了个需求,这种数据,要秒级查询,领导可等不了半小时。然后kylin 的创始人韩卿(Luke Han)(原 eBay 全球分析基础架构部 (ADI) 大数据产品负责人、现 Kyligence 公司创始人),为了解决这个问题,开始研发 kylin。
大数据时代来临,越来越多的企业开始使用 Hadoop 管理数据,但无论是商业还是开源的,在 Hadoop 上始终缺乏一个很好的数据仓库与 BI 解决方案以支持超大规模数据集上快速交互分析能力,现有的商业智能分析工具(如 Tableau,MicroStrategy 等)往往存在很大的局限,如难以水平扩展、无法处理超大规模数据、缺少对 Hadoop 的支持;而利用 Hadoop 做数据分析依然存在诸多障碍,例如大多数分析师只习惯使用 SQL 而不习惯于使用非常工程师的方式访问大数据平台,Hadoop 难以实现快速交互式查询等等。Kylin 就是为了解决这些问题而设计的。
在当时 13 年,业界还没有更好的解决,基于立方体理论预计算的kylin 经过内部验证后是可靠的,在 14 年开源在 github 后,各方大佬前来点赞,然建议 kylin 申请apache 孵化器来获得更好的发展,加入后经历 11 个月后就毕业成为顶级项目!我看专题访谈里韩大哥只是云淡风轻的讲过,这其中的努力和辛苦,或许远比韩大哥淡淡的说很辛苦更辛苦。
当时 kylin 的活跃,可能比我想的更加积极,2015 年kylin 可谓热门,然后我还百度了一下,有人锐评,2015 是大数据的黄金时代,当时炒概念就是炒大数据,在那年,kylin 还获得了一个奖项:infoWorld:Bossie Award,最佳大数据开源奖。同时获得这个奖的有:Hive,Spark,Flink等一众时至今日谁都听过的大数据组件。
可以说十年前差不多时候,当时大数据的皇冠闪闪发光时,kylin 也是上面一颗耀眼的宝石。
 (小温给你跪下了,是我有眼不识泰山)
(小温给你跪下了,是我有眼不识泰山)
后面 kylin 需求日渐发展,创始人韩大哥离开 eBay,建立 kylin 商业化公司,kyligence,这里买个关子,为什么起“kyligence”这个名字呢?
时间拨回到现在,kylin 已经更新到了kylin5.x的版本,有了更多数据源(可拔插),以及查询速度,构建能力进一步加强等,虽然5 版本是上一年(24 年)出的,但至今也是有人再维护,身为后来黄毛小生的我,纵观一下十年时间,从 15 年,就有到 jd,美团等大厂服役,到后面 58 同城,雅虎,搜狐,等一堆说的上名称的互联网公司也有发挥光和热。
小番外,讲讲kyligence
来到 kyligence 官网,观察韩大哥开了快十年的公司,发现他们主要售卖两个服务,一个是基于 kylin 的数据中台服务,另一个是AI 赋能数据服务,说出来可能不信,韩大哥是有远见的,如果 gpt 爆发的 23 年算是AI 元年的话,其实早到19 年,kyligence 就有推出过 AI 增强引擎,因为整个数据链路是麻烦的痛苦的,天天挨业务方骂的,韩大哥很早就想给数据服务 AI 赋能了,这里顺便收回前面的关子,为啥叫 kyligence 呢?拆开看,就是 kylin+intelligent,麒麟加智能,韩大哥的远见,16 年就已经看出。

稍微扯远了,讲 kylin 讲到 kylin 创始人去了。
2.Kylin——cube 是什么玩意?
讲完了光辉历史后,我们还是得脚踏实地啊,回头来我们看看 kylin的技术架构
 可以看出,Kylin 位于数据源与 BI 分析之间,作为 OLAP 计算引擎:
可以看出,Kylin 位于数据源与 BI 分析之间,作为 OLAP 计算引擎:
- 数据源支持: Hive、Kafka、Iceberg 等
- 计算层: 基于 Spark 的分布式计算
- 存储层: HDFS(Kylin5+ 支持 Parquet 格式)
- 下游对接: Tableau、帆软等 BI 工具
下图是 kylin5 多节点的架构
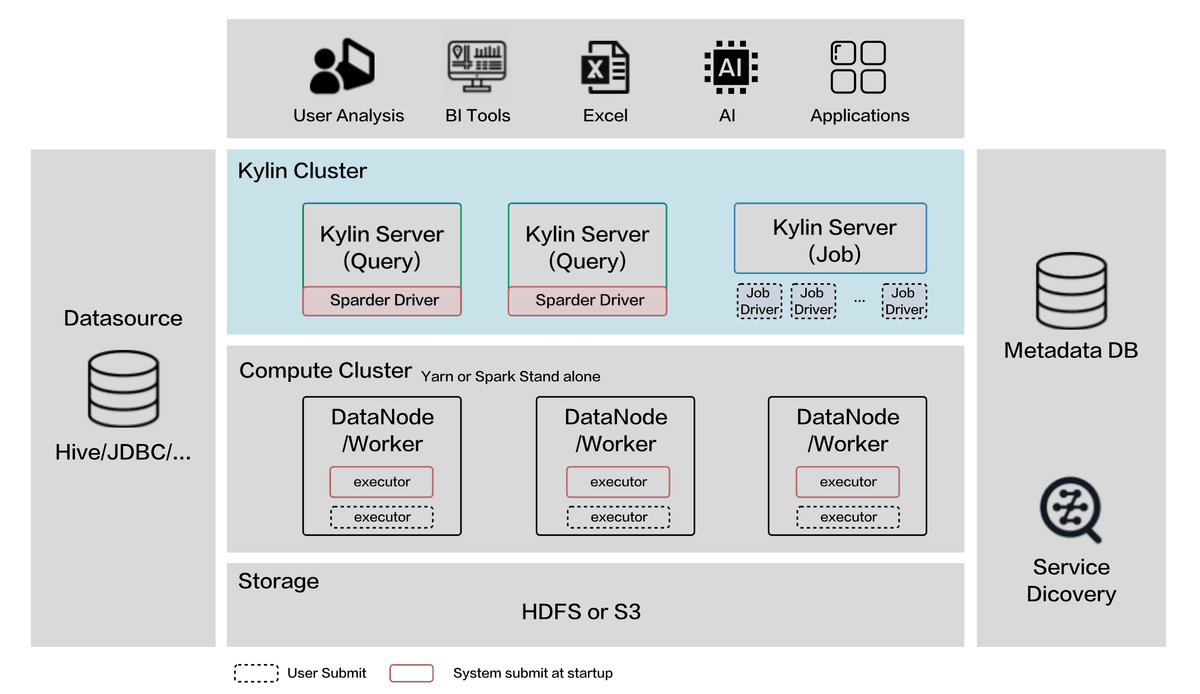
2.1 kylin 安装与配置
这点其实不应该有的,但是我觉得我很想吐槽一下,还是写进来当小番外吧。 kylin5 更新后,远比 4 部署起来简单许多,5 更新了存储可以用 parquet 放到 hdfs,不用再麻烦额外下载 hbase 来当存储数据引擎了,然后 metadata 可以用 mysql 或者 pgsql 来存储。 但即便如此,kylin 的安装还是蛮麻烦的,首先他得先像 hive那样,在 mysql 或者pgsql 里配置 kylin 数据库,当然别忘记了 jdbc 的 jar 包,也是要你自己手动放到 kylin 的 lib 里。 然后把 hadoop 的conf 配置文件夹,和 hive-site.xml等这些文件塞到 kylin 里,最后呢还要在 hdfs 上建立个 kylin 文件夹,这个是给 kylin 用的。 最让人无奈的一点是,他的 spark 只能用 kylin 自带的,我曾经尝试是用自己的 spark 去运行,报错说有些方法没有,亦或许是我自己的问题?查阅了官网,配置时也是叫你用他的脚本下载 spark
 然后我再访问互联网,看到一篇 csdn 文章有写是可以用自己spark 的,但是要怼入很多 jar 包
然后我再访问互联网,看到一篇 csdn 文章有写是可以用自己spark 的,但是要怼入很多 jar 包
 # Apache Kylin 5.0在Ubuntu18.04的部署教程
虽然安装繁琐,但是我们 kylin 还是很有良心的给了个检查脚本,运行./bin/check-env.sh,一步一步跟着 AI 修改,就可以了!
# Apache Kylin 5.0在Ubuntu18.04的部署教程
虽然安装繁琐,但是我们 kylin 还是很有良心的给了个检查脚本,运行./bin/check-env.sh,一步一步跟着 AI 修改,就可以了!
题外话,现在 AI 有个很好用的MCP叫 context7, 他网站汇总了很多文档,能让你 AI 获得项目最新代码,我每次用 AI 都会用一次 context7 保证 AI 的知识是新的,但是 kylin 并没有上传文档到 context7 里 (但是隔壁 doris 有)
2.2 cube 预计算
要说 kylin 最需要知道的,非 cube 莫属,这就是当初 kylin 能威震四方的宝物,在当时大家还在苦恼每天算业务数据 sql 跑的很慢时,kylin 的答案简单但也有效,预计算 这就是 Cube 的核心思想:空间换时间,提前算好!
那什么是 cube 呢?翻译过来就是立方体,这样说肯定是不如图片生动,这里我借鉴一篇博客的图
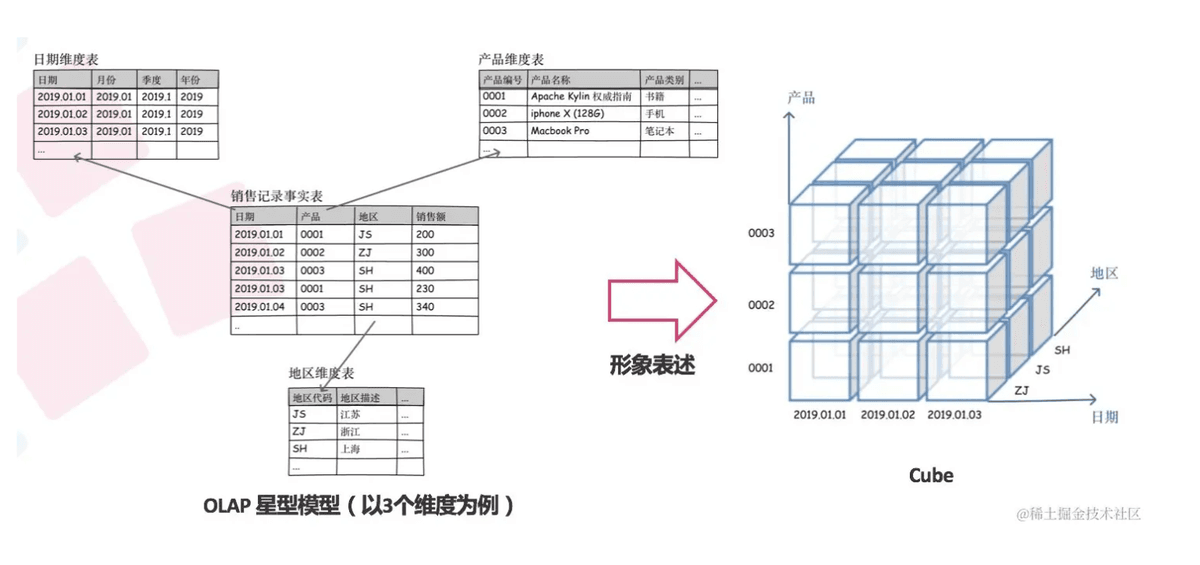
Cube,中文叫"立方体",但它不只是三维的。 在 OLAP 下,预计算能提前先算好数据存好,当真正要用的时候就不用等待了,在 kylin,维度变成了x,y,z轴,度量值按照维度聚合成一个一个 cube
 假设有三个维度,你看可以凑出八个(不是七个吗?但其实我什么维度都没有,也算一个呀小老弟)角度来预聚合数据,当业务要求 x 地区 y 品类的数据时,我们直接拿取角度 4cube 预聚合的数据,再也不用苦苦等待了!
在这里,这个’角度‘,在 kylin 里叫Cuboid:所有维度可能的组合。
假设有三个维度,你看可以凑出八个(不是七个吗?但其实我什么维度都没有,也算一个呀小老弟)角度来预聚合数据,当业务要求 x 地区 y 品类的数据时,我们直接拿取角度 4cube 预聚合的数据,再也不用苦苦等待了!
在这里,这个’角度‘,在 kylin 里叫Cuboid:所有维度可能的组合。
可是这时候又有人会问了,现在三个维度,就有八个 Cuboid,那如果 多点维度呢,比如 10 个维度,这也是业务常有的 我的天!210就是—1024种可能!20 个维度,就是 100 万 这不是妥妥维度爆炸了吗?是叫你拿空间换时间,可没叫你这么糟蹋空间吧
别急,kylin 在这方面有优化 优化策略:
| 优化方式 | 说明 | 效果 |
|---|---|---|
| 聚合组 | 将相关维度归组,组内组合,组间隔离 | 减少无意义组合 |
| Mandatory 维度 | 必须出现在所有 Cuboid 中的维度 | 强制固定,缩小组合空间 |
| Hierarchy 维度 | 具有层级关系的维度(如国家→省→市) | 限制为前缀组合 |
| Joint 维度 | 必须同时出现的维度(如品牌+型号) | 避免单独排列组合 |
如果现在 kylin 是和面试会问到的话,cube 如何防止维度爆炸,一定是很经典的面试题!
现在回过头来,我们现在在提前预先构筑好了 cube,那我们查询起来那时间肯定是大大减少了,比如
SELECT region, SUM(sales)
FROM orders
WHERE date = '2024-01'
GROUP BY region
我们可以看到维度有,region,date,那我们直接命中(region,date)的 cube,秒拿数据,再也不用夹在业务催促和数据跑的慢两难之间了。
2.3 cube 的更新
现在再回头看看领导对我们说的话,见到还有一个角度“数据更新方式”,这时候你一拍大腿是啊! 我半夜跑半天把 cube 算好,但如果假设,哪一天业务突然要求,今天的数据也要加进去,那我不是得重跑构筑 cube?
别急,cube 不会全量更新耽误你的时间,Kylin 支持增量构建 + Segment 合并,不需要全量重建。 我们再剖开 cube 一看,它里面有很多一句时间分区的 segment,新来的数据不大,我们新数据单独构建 cube,然后里面就是新时间的 segment,那我们两个合并,就是全新的 cube 了!
3.kylin 的技术局限
15 年的璀璨明珠现在用的少了,在我看来,还是主要有三点,第一,硬件迭代太快,第二,分析需求变多,最后就是,运维难度太高。
硬件的迭代,让你不得不感慨力大砖飞这四字词语真是真理,我让 AI 联网搜了一下
| 时间节点 | 服务器配置 | 网络环境 | 预计算价值 |
|---|---|---|---|
| 2013-2015 | 内存:32-64GB CPU:8-16核 SSD:512GB-2TB |
4G时代 千兆网卡少见 |
极高 预计算显著提升性能 |
| 2025 | 内存:TB级 CPU:64核+ SSD:7-15TB |
千兆网卡普及 万兆网络常见 |
降低 实时计算成本下降 |
分析: 硬件性能的指数级提升(摩尔定律),使得"力大砖飞"成为可行方案,削弱了预计算的技术优势。
力大砖飞不是盖的,你可以说那我可以有更多 cube,那何必呢?我能直接算,为什么还要用麻烦预计算呢,时间 1ms 出数据和两三秒出数据,并不是需要为此特意上 cube 的理由了。
第二点就是业务需求演技的原因,前面一直在夸 kylin,可是kylin 还是有点太死板,cube 预计算的代价,就是可能每天分析的数据维度是变化不大的,kylin 刚性太强,如果业务方需求变化多样,kylin 就有点难以胜任了,在这里,有一个专业名词叫 Ad-hoc
Ad-hoc,即席查询(Ad-hoc Query),就是实现没有预定义,临时想查什么的查询
这点 kylin 的确是比较难做到,或许以前,流行的 T+1 固定报表,每天计算区域售卖,同比环比这类,可是现在是数据时代,每一个点都能成为分析的点,以前可能是为了迎合大部分人去业务数据分析,现在巴不得是千人千面,每个人精确打击,每个人都钱都要赚到,比如音乐平台,要更懂你的音乐品味,音乐分类不再是周杰伦唱的这么简单,而是你这个人是 37.1% 摇滚,22.2% 流行这么细致的划分 (当然是有点夸大说法哈,毕竟我自己没真正去过真实生产环境),数据要求更精细了,kylin 想要做到,那之前说的维度爆炸问题,实在没办法避开了。
kylin 在当年,的确是体现出来自中国的智慧,那时候内存小,硬件贵,预计算的方法,kylin 用架构聪明的规避了硬件瓶颈,的确极大提升了那时候 OLAP 的分析能力,但这种”提前“,肯定是要在灵活性上吃亏的,你可能在穷游前预计算了很多种情况,算出了一个可行的旅行方案,可是真正旅游时,可能地震了呢。。。。
最后 kylin 最无法避开的一个大问题,就是运维成本较高,kylin 是计算引擎,他需要有 hadoop,hive,spark,zookeeper 等大数据组件,运维难度不是一般的高,出了问题可以排查的点有很多,然后 cube 的优化也是难点,运维的成本,也是公司考虑是否使用该架构不得不考虑的点。
4.Doris,来自百度的Palo~
我一直以为doris 的开始是17 年百度的 palo,然后我查阅网络时,发现 doris 曾在 21 年发过一篇文章 Doris 简史 - 为分析而生的 11 年 惊了!原来 doris 才是真正的老资历啊!不过在那之前都是百度内部使用,我们还是从开源的前后时候说起吧。 当时百度也是在 OLAP 的大数据分析下焦头烂额,当时业务痛点就是要支持高并发查询,然后百度的大数据研发部自研开发了Palo,一个现代 MPP(大规模并行处理)分析型数据库。 17 年 Palo开源,这个名字非常有意思,把它反过来,就是 OLAP,意思是玩转 OLAP,在 17 年百度内部使用非常成熟后,百度认为这项技术也能帮助更多的人更加高效、方便的支持类似的业务需求。于是在 github 开源,第二年贡献给了 apache 社区,并正式改名为 Apache Doris。
为啥不叫 Apache Palo呢? 听说 Palo有商标占用了,然后当时数据库领域还有Cassandra、Aurora这些项目,都是拿古神话的女神名字作为命名,Cassandra(图标是卡姿兰大眼睛那个)是古希腊神话里有预言能力的女神,但是他预言的代价是没人信她的话,而Aurora (数据库管理系统)是古罗马神话的黎明女神,起这种女神名字的确帅哈,于是 Palo改名为 doris,这一位来自古希腊神话的海仙女,象征海洋的咸水,泡沫,海浪等特性。 当然只是一个名字而已,没有别的含义。沿用这种风格,代表了 Doris融入了 apache 的大家庭
虽然时间没有kylin 神速,但是历经四年后,doris 也是顺利毕业成为 Apache顶级项目,22 年 doris 版本为 1.1.2,全球贡献者超过 300 人,用户已经覆盖金融,互联网,物流,制造等多个行业。
后面doris 凭借自己优秀架构和性能,在 22 年至今,进入了蓬勃发展的黄金时期,在前不久就已经迭代到 4.0,而且影响力进一步扩大, Doris 在中国乃至全球范围内拥有广泛的用户群体。截至目前,Apache Doris 已经在全球超过 5000 家中大型企业的生产环境中得到应用。在中国市值或估值排行前 50 的互联网公司中,有超过 80% 长期使用 Apache Doris,包括百度、美团、小米、京东、字节跳动、阿里巴巴、腾讯、网易、快手、微博等。同时,在金融、消费、电信、工业制造、能源、医疗、政务等传统行业也有着丰富的应用。
在中国,几乎所有的云厂商,如阿里云、华为云、天翼云、腾讯云、百度云、火山引擎等,都在提供托管的 Apache Doris 云服务。
另外,4.0 的 doris 开始拥抱 AI,这里更新的点我觉得非常好玩,但是先不在这里讲,我们后面再提。
5.Doris 架构:重剑无锋,大道至简
先还是讲讲 Doris的使用场景,还记得前身名字 Palo玩转 OLAP 的梗吗,Doris 就是广泛应用于 OLAP 分析场景,如下图:
 这里直接套官网的讲解:
Apache Doris 主要应用于以下场景:
这里直接套官网的讲解:
Apache Doris 主要应用于以下场景:
-
实时数据分析:
-
实时报表与实时决策: 为企业内外部提供实时更新的报表和仪表盘,支持自动化流程中的实时决策需求。
-
交互式探索分析: 提供多维数据分析能力,支持对数据进行快速的商业智能分析和即席查询(Ad Hoc),帮助用户在复杂数据中快速发现洞察。
-
用户行为与画像分析: 分析用户参与、留存、转化等行为,支持人群洞察和人群圈选等画像分析场景。
-
-
湖仓融合分析:
-
湖仓查询加速: 通过高效的查询引擎加速湖仓数据的查询。
-
多源联邦分析: 支持跨多个数据源的联邦查询,简化架构并消除数据孤岛。
-
实时数据处理: 结合实时数据流和批量数据的处理能力,满足高并发和低延迟的复杂业务需求。
-
-
半结构化数据分析:
- 日志与事件分析: 对分布式系统中的日志和事件数据进行实时或批量分析,帮助定位问题和优化性能。
Doris 的架构真的可以说,非常简单,用武侠小说里的形容套进去,就是大道至简,重剑无锋。 Apache Doris 采用 MySQL 协议,高度兼容 MySQL 语法,支持标准 SQL。用户可以通过各类客户端工具访问 Apache Doris,并支持与 BI 工具无缝集成。 Doris 有两种玩法,一种是存算一体:
- Frontend (FE): 主要负责接收用户请求、查询解析和规划、元数据管理以及节点管理。
- Backend (BE): 主要负责数据存储和查询计划的执行。数据会被切分成数据分片(Shard),在 BE 中以多副本方式存储。
 其中,FE(Frontend)分为三种角色,Leader(Master),猜都猜得出就是负责元数据读写,然后 Follower,就是我们的备份选手,一旦 Master 寄了火速顶上,Observer 就是没有争夺皇位的打工仔,主要目的是增加集群的查询并发能力。Observer 节点不参与集群的选主过程。
其中,FE(Frontend)分为三种角色,Leader(Master),猜都猜得出就是负责元数据读写,然后 Follower,就是我们的备份选手,一旦 Master 寄了火速顶上,Observer 就是没有争夺皇位的打工仔,主要目的是增加集群的查询并发能力。Observer 节点不参与集群的选主过程。
BE 就是我们真正干活的地方,主要负责数据存储和查询计划的执行。数据会被切分成数据分片(Shard),在 BE 中以多副本方式存储
那一体肯定是不能满足大家的,我们程序员就是讲究一个低耦合,不希望一个炸了,别的跟着炸,于是 doris3.0 后,大家可以选择 doris 的存算分离架构

- 元数据层: 负责请求规划、查询解析以及元数据的存储和管理。
- 计算层: 由多个计算组组成。每个计算组可以作为一个独立的租户承担业务计算。每个计算组包含多个无状态的 BE 节点,可以随时弹性伸缩 BE 节点。
- 存储层: 可以使用 S3、HDFS、OSS、COS、OBS、Minio、Ceph 等共享存储来存放 Doris 的数据文件,包括 Segment 文件和反向索引文件等。
6.Doris技术特点:存储模型和物化视图
本来按照上文,我应该这个章节细细写写 doris 的存储引擎和查询引擎等等,但是我在 kylin 时写了 kylin 最有特色的 cube,那这里介绍一下 doris 与之很相似的存储模型和物化视图 doris 本质是数据库,是写 sql 的,那就避不开要建表,在 Doris 中建表时需要指定表模型,以定义数据存储与管理方式。在 Doris 中提供了明细模型、聚合模型以及主键模型三种表模型,可以应对不同的应用场景需求。不同的表模型具有相应的数据去重、聚合及更新机制。选择合适的表模型有助于实现业务目标,同时保证数据处理的灵活性和高效性。
在 Doris 中支持三种表模型:
- 明细模型(Duplicate Key Model):允许指定的 Key 列重复,Doirs 存储层保留所有写入的数据,适用于必须保留所有原始数据记录的情况;
- 主键模型(Unique Key Model):每一行的 Key 值唯一,可确保给定的 Key 列不会存在重复行,Doris 存储层对每个 key 只保留最新写入的数据,适用于数据更新的情况;
- 聚合模型(Aggregate Key Model):可根据 Key 列聚合数据,Doris 存储层保留聚合后的数据,从而可以减少存储空间和提升查询性能;通常用于需要汇总或聚合信息(如总数或平均值)的情况。 在建表后,表模型的属性已经确认,无法修改。针对业务选择合适的模型至关重要:
- Duplicate Key:适合任意维度的 Ad-hoc 查询。虽然同样无法利用预聚合的特性,但是不受聚合模型的约束,可以发挥列存模型的优势(只读取相关列,而不需要读取所有 Key 列)。
- Unique Key:针对需要唯一主键约束的场景,可以保证主键唯一性约束。但是无法利用 ROLLUP 等预聚合带来的查询优势。
- Aggregate Key:可以通过预聚合,极大地降低聚合查询时所需扫描的数据量和查询的计算量,非常适合有固定模式的报表类查询场景。但是该模型对
count(*)查询很不友好。同时因为固定了 Value 列上的聚合方式,在进行其他类型的聚合查询时,需要考虑语意正确性。
(好爽,官网写的好好,直接 cv) 我们特别看那个聚合模型,是不是也有预计算的味道,表建好后,以后 load 数据进来后自动触发计算来汇总信息,而且存进来的数据聚合后还能减少空间。
然后就是我觉得和 cube 一样风味的物化视图了 官方文档的一句话:物化视图是既包含计算逻辑也包含数据的实体。这个计算逻辑,如果说是按维度聚合,不就是 cube 了吗! 然后文档还写道:物化视图根据 SQL 定义计算并存储数据,且根据策略进行周期性或实时性更新。物化视图可直接查询,也可以将查询透明改写。它可用于以下几个场景:
-
查询加速:在决策支持系统中,如 BI 报表、Ad-Hoc 查询等,这类分析型查询通常包含聚合操作,可能还涉及多表连接。由于计算此类查询结果较为消耗资源、响应时间可能长达分钟级,且业务场景往往要求秒级响应,可以构建物化视图,对常见查询进行加速。
-
轻量化 ETL(数据建模):在数据分层场景中,可以使用物化视图的嵌套来构建 DWD 和 DWM 层,利用物化视图的调度刷新能力。
-
湖仓一体:针对多种外部数据源,可以将这些数据源所使用的表进行物化视图构建,以此来节省从外部表导入数据到内部表的成本,并且加速查询过程。 预计算查询加速,怎么样,是不是和 cube 有点异曲同工之妙? 而且我认为物化视图比较灵活,因为构建物化视图就类似,把你平时用的 sql,这个查询过程封装起来,到时候可以直接拿来用,但我们还是要辩证的往下看。 物化视图分为同步物化视图和异步物化视图 同步物化视图(Sync Materialized View) 特点:
- 实时更新:基表数据变更时,物化视图立即同步更新
- 强一致性:保证查询结果与基表数据强一致
- 查询透明:用户查询基表时,Doris自动改写到物化视图,无需手动指定
- 限制较多:只支持简单的聚合操作(SUM、COUNT、MAX、MIN等),不支持多表JOIN 不支持 join 那很伤啊
异步物化视图(Async Materialized View) 特点:
- 定时/手动刷新:支持定时任务或手动触发刷新
- 弱一致性:数据可能有延迟,但查询性能更高
- 功能强大:支持多表JOIN、复杂聚合、嵌套物化视图
- 灵活调度:可设置刷新策略(每小时、每天等)
这里看出,同步就是数据及时更新很快,自动实时同步,但是只支持单表简单查询,异步呢就是数据来了得等会,定时同步或者手动同步,但是支持复杂查询,前者像实时的 cube,后者像灵活性更高的 cube
7.最后的八角笼:为啥 doris 更好点呢
其实讲到现在,大家大致了解了 kylin 和 doris 后,肯定会狠狠炮轰我的标题,kylin 是计算引擎,doris 是分析型数据库,如果比喻,前者是 CPU,后者是整个计算机(类似),这二者怎么可以比呢,其实我写着的时候也有这么觉得,但是理性的说,doris 架构更简单,不用很复杂的 hadoop 体系,在未来越来越多公司数字化时,这种成本比较低,运维难度低,但是性能又好的分布式数据库肯定是大多公司的优先选择,doris 不单是挑战 kylin,其实更多是挑战整个 hadoop 体系,当初大数据概念抄的最火热的时候,不管数据量大小 hadoop 先装上先,其实或许装个 mysql 都能应付的过来,现在 大数据这个概念沉淀下来了,人们都清楚了数据是一切事物的底座,他早已融入了互联网的方方面面,听到大数据就是很理所应当,在技术选型时,公司会更慎重考虑,自己的数据量,运维的成本,易用性等,不是说 hadoop 不行,hadoop 从 2003 年 mr 文章的问世,到现在 22 年,大数据的沉沉浮浮是离不开 hadoop 的,只是说 doris 一个数据库可以完成的任务,或许的确没有必要上分布式数据存储了。而且现在云技术越来越先进,或许搞半天,还不如上云。
但是还是扯回来,我还是拿这两个组件打一下八角笼,我个人是偏爱 doris,有失偏颇,我直接问 AI 来给大家看结果,我首先问 AI 两个大数据组件进行比拼,要从哪几个方面比较,然后按照这个我分别问 openai,gemini,qwen,DeepSeek,豆包,kimi,然后要求他们综合下来给二者其中一票,绝对公平公正 提示词如下,我额外加了一句:综合考虑,你会给谁投上一票
 最终票数比例 kylin vs doris —— 1:6(ChatGPT 这小伙汁两边都投了)
最终票数比例 kylin vs doris —— 1:6(ChatGPT 这小伙汁两边都投了)
但是记得我们的问题,什么场景下优先选 A?
- 超大规模固定报表:千亿行+、100+维度组合的预定义报表(如财务月报),要求 P99 < 500ms 且数据延迟可接受小时级(T+1)。
- 遗留 Hadoop 生态深度绑定:企业已投资 HBase 集群,且无实时需求,需最小化改造成本。
- 资源极度受限:计算资源紧张,但存储廉价(Cube 膨胀 5~10 倍),需用存储换 CPU。
如果每天报表需求固定,时间要求还的确非常高,不是说 2s也行,就是要亚秒级别,比如银行啊,航天公司等,kylin 还是优先,或者公司本来就已经有成熟 hadoop 系统,而且实时要求并不高,kylin 也还是能给公司带来新血液。 不过时代日新月异,我翻了翻评论,很多人都在说维度越来越多,预计算越来越慢,的确没办法了,kylin 得下线了。
日后会不会 kylin 又有神更新,让他在 hadoop 的体系下使得焕发第二春?我不得而知,现在让我在结尾前中断一下,还记得我在前面说的,doris4 有一个让我觉得很有意思的更新的点吗?现在先回收这点,doris 在 4.0版本,引入了 AI 函数库,没错,就是你写 sql 顺便调用 AI 帮你分析,官方文档在 4.0.0 Release 文档是这么说的:
AI Functions 函数库让,数据分析师能够直接通过简单的 SQL 语句,调用大语言模型进行文本处理。无论是提取特定重要信息、对评论进行情感分类,还是生成简短的文本摘要,现在都能在数据库内部无缝完成
 然后还给出了一个很有意思的样例:
然后还给出了一个很有意思的样例:
CREATE TABLE candidate_profiles (
candidate_id INT,
name VARCHAR(50),
self_intro VARCHAR(500)
)
DUPLICATE KEY(candidate_id)
DISTRIBUTED BY HASH(candidate_id) BUCKETS 1
PROPERTIES (
"replication_num" = "1"
);
CREATE TABLE job_requirements (
job_id INT,
title VARCHAR(100),
jd_text VARCHAR(500)
)
DUPLICATE KEY(job_id)
DISTRIBUTED BY HASH(job_id) BUCKETS 1
PROPERTIES (
"replication_num" = "1"
);
INSERT INTO candidate_profiles VALUES
(1, 'Alice', 'I am a senior backend engineer with 7 years of experience in Java, Spring Cloud and high-concurrency systems.'),
(2, 'Bob', 'Frontend developer focusing on React, TypeScript and performance optimization for e-commerce sites.'),
(3, 'Cathy', 'Data scientist specializing in NLP, large language models and recommendation systems.');
INSERT INTO job_requirements VALUES
(101, 'Backend Engineer', 'Looking for a senior backend engineer with deep Java expertise and experience designing distributed systems.'),
(102, 'ML Engineer', 'Seeking a data scientist or ML engineer familiar with NLP and large language models.');
创建了两个表,一个是候选人资料,有姓名和自我介绍两个字段,另一个表是 jd,就是工作-工作要求表,然后分别插入了三个候选人,和两份工作 现在 doris 可以通过AI_FILTER把职业要求和候选人简介做语义匹配,筛选出合适的候选人:
SELECT
c.candidate_id, c.name,
j.job_id, j.title
FROM candidate_profiles AS c
JOIN job_requirements AS j
WHERE AI_FILTER(CONCAT('Does the following candidate self-introduction match the job description?',
'Job: ', j.jd_text, ' Candidate: ', c.self_intro));
+--------------+-------+--------+------------------+
| candidate_id | name | job_id | title |
+--------------+-------+--------+------------------+
| 3 | Cathy | 102 | ML Engineer |
| 1 | Alice | 101 | Backend Engineer |
+--------------+-------+--------+------------------+
但是这里我没仔细看哈,里面原理是啥我也不知道。但是你不觉得,很有意思吗?以前老是说 sqlboy,现在他们也跟着玩起来 AI 哦。但借此也可以结尾了,在现在 AI(现在猛猛炒的概念)的浪潮下,我本来标题是,新时代正在到来,看了看 doris,我又改了改
新时代已经到来。
叠甲:本篇文章通篇都是技术探讨,绝对没有踩一捧一,看不起技术拉踩等恶劣行为,虽然 kylin 在文章里似乎显得很 low,但事实是作者黄毛小二给 kylin 提鞋都不配,只是领导一番劝诫,让我有了写下此篇文章的想法。
参考资料
^1: Apache Kylin 成长之路对话 [^2]: Doris 简史 - 为分析而生的 11 年 [^3]: 什么是麒麟(kylin)?查数据贼快的哟 [^4]: Apache Kylin 5.0在Ubuntu18.04的部署教程 [^5]: doris 官方文档